




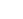
1、 Llama3◆■★★◆■.1 训练平均 3 小时故障一次,H100 万卡集群好脆弱,气温波动都会影响吞吐量
浚星供应链是一家综合性供应链解决方案提供商,其业务集供应链规划设计、仓储管理、运输配送和信息服务于一体。

4、数字化营销系统服务商「创聚收科技」完成2000万人民币天使轮,投资方为复兴资本★◆◆◆。
liblibAI是一家AI绘画原创模型平台,致力于激发原创AI模型◆★★★、素材的创作,提供更新,更全★■★、更热门的素材★■◆,并与各位AI绘画爱好者一同拓宽AI的边界。
这不就和老师判卷是一个道理么?书写工整、格式清晰或者“多写点总没错■★■★”的卷子★■■,总是能多捞点分数……OpenAI 原来是拿捏住了人类的心理啊■★◆■◆■。
2■■◆★★■、GPT-4o mini 凭什么登顶竞技场?OpenAI 刷分秘诀被扒★■◆★■,原来奥特曼早有暗示
除了 GPU 外的另一半故障由众多因素导致,比如软件 Bug、网络电缆等等◆★★。
更多干货分享敬请关注我们的公众号与视频号~超多精彩对话内容等待您的解锁!
除了要贴近相关领域★★■,另一种在预训练阶段使用合成数据的例子当属 Phi-1.5 模型,目的是注入逻辑推理能力◆■★★。
先让模型对同一问题创建多个响应,然后让奖励模型对这些相应的质量进行反馈。这种方法属于从 AI 反馈中进行强化学习(Reinforcement Learning from AI Feedback◆◆★, RLAIF)。(新智元)
比如★★,要让模型提高逻辑推理能力、实现更好的代码生成和函数调用,或者提升阅读理解类任务的表现,都可以通过微调来实现。
用合成数据微调基座模型★★◆,可以更好地应用于实际场景★■■■。例如,在金融领域改进风险评估、在零售领域优化供应链、在电信领域提升客户服务,以及在医疗领域改善患者护理等等。
在这种情况下,我们可以先让大模型完成任务★★■★◆◆,再使用这些数据指导小模型进行。
可以创建一个包含指令模型(instruct model)和奖励模型(reward model)的流水线来实现这个需求。
Llama 3.1■◆★★★◆、GPT-4 这种通用 LLM◆◆★★★■,一般需要互联网规模的数据。而特定领域的 LLM(如几何学■★、放射学★◆、电信行业等)则需要注入相关的领域信息■◆,这个过程被称为领域自适应预训练(Domain Adaptive Pretraining,DAPT)◆★★◆。
一个人钻研的愈多◆★◆■■,他学习到的愈多,一个人学习到的愈多,他愈了解到他所知道的何其浅薄★★。
湾区黄金枢纽之上,有灵魂与底蕴的「世界庄园」广佛新世界◆◆◆,打版第四代高质量住宅!
终于★★■◆,官方晒出了一份完整数据,展示了 GPT-4o mini 参与的 1000 场 battle,包括在不同语言下和不同模型的 PK 情况。
实际上,合成数据在 AI 领域的应用已经有十多年的历程■■■★,比如物体检测或分类系统中曾经的数据增强技术。
Self-Instruct◆★■★、WizardCoder★■◆■、Alpaca 等模型都通过创建特定领域的数据并进行微调◆■★★,来定向提升模型能力。
这篇博客文章将介绍几个合成数据的生成与应用案例,并就其中一个进行深入探讨。
让我们来看看如何实现这一目标。训练语言模型通常包括三个步骤:预训练、微调和对齐(alignment)◆◆★■◆★。
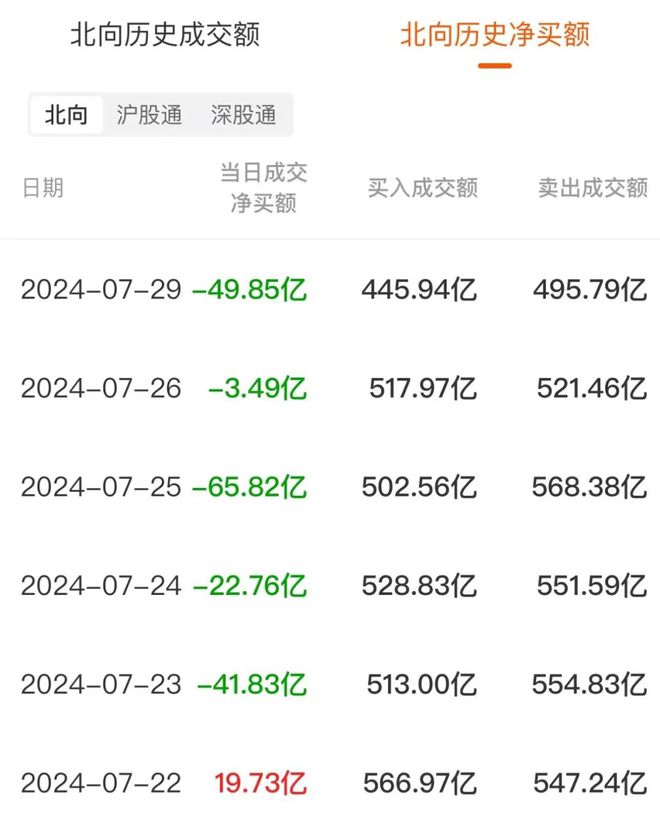
网友表示,自己在竞技场中如果遇到有的模型拒绝回答■■◆,他就会觉得模型弃权比赛◆★■★★,因此更愿意判另一个模型胜出。而且更清楚的回答格式★★■◆,也能让人更容易找到信息。
Llama 3.1 在为期 54 天的预训练期间,经历了共 466 次任务中断。其中只有 47 次是计划内的,419 次纯属意外,意外中 78% 已确认或怀疑是硬件问题导致■◆★◆。
真实数据稀缺可能不再是问题了◆◆■■,Nemotron 9T token 的预训练预料中◆◆★,98% 都是合成数据。
创聚收科技是一家数字化营销系统服务商■★■,该公司主要从事软件开发、软件销售、人工智能基础软件开发★★■、先享后付系统开发等相关业务◆■■■◆★。
适逢 Llama 3.1 模型刚刚发布◆■◆★★◆,英伟达就发表了一篇技术博客,手把手教你如何好好利用这个强大的开源模型,为领域模型或 RAG 系统的微调生成合成数据★◆◆★。
不过最终,Llama 3.1 团队保持了超 90% 的有效训练时间。只有三起故障需要人工大幅介入,其余的都自动化处理了。 ( 量子位 )
哪怕后面 lmsys 做过一次声明,表示大家别只看总榜★★,还要更关注细分领域的情况。也没能让大家满意★★■◆◆◆,不少人觉得 lmsys 就是从 OpenAI 那收钱了。
扫码加入【极新】科技行业交流群,探索科技前沿趋势◆★★◆■★,本群适合创始人、CXO◆★★★★★、行业高管。
尤其是考虑到 Llama 3.1 有如此大的参数规模★◆■◆★,加上丰富的 15.6T token 训练数据★■,非常适合用于数据生成。
3、综合性供应链解决方案提供商「浚星供应链」完成3000万人民币A轮融资,投资方为复兴资本。
相较于 Claude,它的记忆力更差◆■★★,过一会儿就会忘记上下文内容。以及 Claude 一次就能修好的 bug,换到 GPT-4o 那里,甚至需要 20 次■■★★、耗时 1 小时★■★■◆■。
合成数据并不是「从无到有」地创造新信息,而是对现有信息进行转换,生成不同的变体。
尤其是 405B 开源巨兽 Llama 3.1 最近正式上线,既可用于批处理和在线推理,也可以作为基座模型,进行特定领域的专门预训练或微调◆◆■★★■。
3■★■◆◆、 英伟达最新技术分享★★◆■◆◆:手把手教你用 Llama 3.1 合成数据改进模型!
也许你还对合成数据存在顾虑,或者不知道如何应用 LLM 驱动数据生成。或许,英伟达的这篇博客可以提供答案。
极新是垂直于产业AI的创投和行业研究媒体,致力于陪伴和记录科技企业进步和产业成长◆■★■★■。已与多家平台和创新企业深度对话和合作★◆◆■,包括华为云■■★★、阿里云、百度智能云◆■■、金山云★■■◆、飞书、火山引擎、钉钉★◆■、东软、Zoho★◆◆★■、容联云、百家云等平台企业,以及智谱AI、百川智能◆■■◆◆、格灵深瞳★★★■◆、深势科技、百图生科、瑞莱智慧★■★◆、创客贴★★◆■◆、生数科技等高成长公司■◆◆◆。
掌握了语言的一般结构后,下一步就是微调,让模型更好地遵循指令■■、完成特定任务。
泽景科技是一家智能HUD解决方案供应商■◆◆■◆★,专注于提供座舱视觉方案,核心产品为HUD。产品线覆盖W-HUD、AR-HUD、 CMS、透明A柱、透明窗口显示等智能座舱相关领域★★。泽景致力于通过自主创新、正向研发,在提高汽车智能化体验的同时,让AR-HUD成为座舱交互的中枢,从而提升驾驶的安全性。
我们是垂直于企服和硬科技的创投和行业研究媒体,致力于陪伴和记录科技企业进步和产业成长。
2、AI绘画原创模型平台「liblibAI」完成数亿人民币股权投资★◆◆★◆■,投资方为明势资本。

县长转给教育局长一篇文章,老师看后纷纷表示:“我们也要做这样的好老师!”
具体来看,在 419 次意外中断中,148 次(30.1%)是由各种 GPU 故障(包括 NVLink 故障)引起的,72 次(17.2%)可以具体到是由 HBM3 内存故障引起。
A股三大指数今日涨跌不一◆★,截止收盘,沪指涨0.03%◆◆■■,收报2891★■★★.85点;深证成指跌0.96%,收报8514.65点◆■★★◆◆;创业板指跌1■◆.44%,收报1635.67点。沪深两市成交额仅有5859亿元,较上周五缩量201亿元★■。 ( 东方财富研究中心 )
1、Llama3★◆◆◆.1 训练平均 3 小时故障一次,H100 万卡集群好脆弱★◆,气温波动都会影响吞吐量
最后,我们希望确保模型响应的风格和语气与用户期望一致★★◆■◆,例如听起来像对话、具有适当的详细程度、复杂性、一致性等◆■。
3、英伟达最新技术分享◆★:手把手教你用 Llama 3★◆■.1 合成数据改进模型!
自我改进则是让同一个模型评判自己的推理过程★★◆,常被用于进一步磨炼模型的能力。

Epoch AI 上个月刚刚发文预言「数据墙」迫近,结果英伟达转头就甩出了 340B 开源巨兽 Nemotron★■◆★■。
1、智能HUD解决方案供应商「泽景科技」完成战略投资■■◆◆,由众擎资本领投,架桥资本跟投。
鉴于 H100 的 700W 高功耗和热应力,出现这样的结果也并不意外★★★■。
2、GPT-4o mini 凭什么登顶竞技场■◆◆?OpenAI 刷分秘诀被扒★★■★,原来奥特曼早有暗示
好玩又好用!华为nova 13系列成为年轻人首选“最具性价比5G手机”!
但在竞技场评分中,GPT-4o mini 还是位居前列。 ( 量子位 )
知识蒸馏是将大模型的能力转移到较小模型的过程★■,但不是简单地在同一个数据集上训练两个模型◆■◆,因为较小模型很难学习到底层数据的准确表征。
有人表示,真的很开心看到大模型因为过高道德边界而导致分数不高的情况■◆■◆◆■。之前他为了用好这些道德感强的大模型(Claude、Gemini 等),总是要精心设计每一个提示词,好心累。
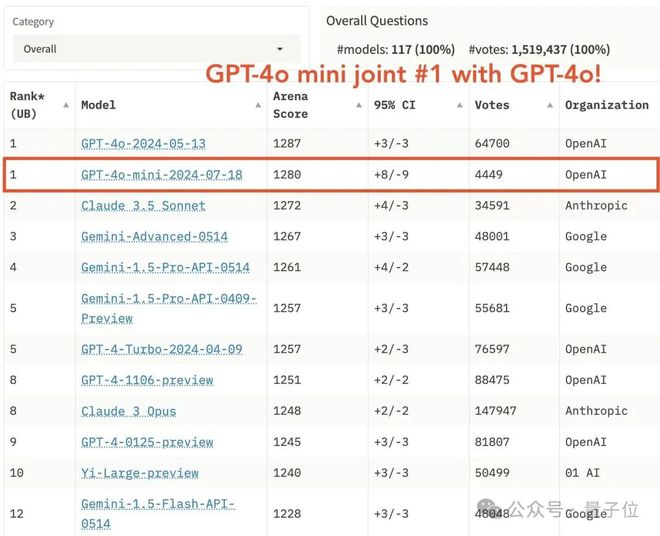
7月29日,两市震荡分化★★,沪指微涨,创指跌超1%。北向资金今日净卖出49.85亿元◆■★◆◆★,已连续5天净卖出;全天成交941.72亿元,占A股总成交额的16★★.07%。 ( 广州日报新花城 )
实际上,在 GPT-4o mini 刚刚发布时,奥特曼就暗示了这次特意的优化:
不过 GPT-4o minni 也不是没有缺点。在数学任务上,它的表现就差了很多。
特别声明★★:以上内容(如有图片或视频亦包括在内)为自媒体平台★★◆◆◆“网易号”用户上传并发布◆■★★■★,本平台仅提供信息存储服务。
这两天■■★★,lmsys 竞技场公布了一份充满争议的榜单。其中才面世不久的 GPT-4o mini 和满血版并列第一★■■★◆,把 Claude 3.5 Sonnet 甩在身后■◆■★◆。
要让 LLM 生成基于最新信息的有根据的响应,构建 RAG 流程十分重要,而且模型响应的准确性取决于流程的质量。
